
Published Apr 15, 2021 · Updated Apr 17, 2021
We compare polarized training, threshold training and AI optimized endurance training. AI optimized training yields the best results, followed by polarized training with threshold training in third. The results are inline with current exercise physiology research. If the training composition is not optimized to the individual athlete, substantially smaller gains are to be expected.
In conventional exercise physiology research studies, randomized controlled trials are performed on a population of participants. For instance, the participants perform certain training routines and the results are analyzed as factual changes of a performance indicator on the population, see for example [1-9].
Here we employ a different approach: every participant has a 'digital twin' - a machine learning model/neural network that is trained on the individual's historical exercise data. The model represents how the athlete individually responds to different training inputs in terms of training volume and composition. It can be used to predict the athlete's performance changes when following a certain training routine, within a margin of error.
This approach allows orders of magnitude higher statistics compared to conventional studies, as the digital twin can execute thousands of different training routines. On the other hand, a human participant can only execute at most a few. Conventional studies are tedious, expensive, take a long time, and have generally low number of participants. We rely on neural networks to simulate the complex exercise response cycle of the human body. A limitation of the digital twin approach, however, is that a certain bias is introduced via the choice of data processing and machine learning model.
AI optimized training (AIO) as used by AI Endurance is based on the individual athlete's historical data. In the first step, the machine learning algorithm 'learns' to be able to predict the athlete's performance by fitting the athlete's data and evaluating the prediction error. In the second step, AI Endurance finds the optimal training routine to reach peak performance at the athlete's goal event date by selecting the training plan with the largest predicted performance gains.
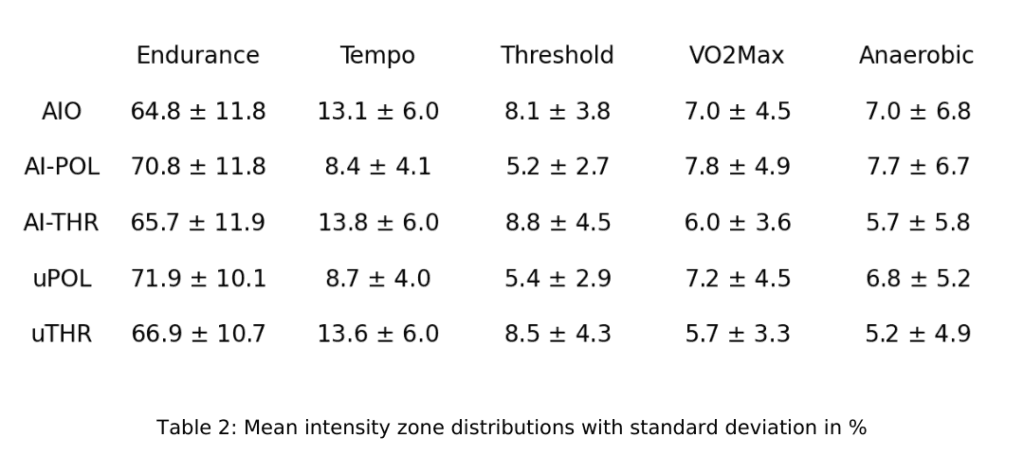
AI Endurance training plan is based on 5 intensity zones (Endurance, Tempo, Threshold, VO2Max, Anaerobic). For cycling, we define these as less than (75, 90, 106, 120, -) percent of FTP. For running, less than (75, 85, 95, 100, -) percent of 5k/VO2Max pace. Read more on AI Endurance's training zones.
A crucial problem when looking for the optimal training input is the extrapolation problem in machine learning [10]: one can only infer reliable predictions reasonably close to the data the neural network has been trained on. In this case, we restrict the possible input data up to one standard deviation away from the mean of the athlete's historical data. For instance, take an athlete with a mean of 1 hour and a standard deviation of 10 minutes for a Tempo intensity zone. The algorithm will explore the 50-70 minute range when looking for an optimal training plan. Conversely, if an athlete has never spent any time in a certain zone, the plan finding can't reliably explore this zone as there is no input data to learn from and hence we discard the zone. These limitations are important when discussing more static training inputs such as polarized and threshold training in the next sections.
AIO is the optimal training plan that can be inferred from an input space defined by the variety of the athlete's historical data. The algorithm is un-biased in that it is agnostic towards any training principle or philosophy. It simply tries to optimize the athlete's goal event performance by finding an optimal training plan in terms of times spent in certain intensity zones.
Polarized training (POL), see for example [1,2], is a training principle that favours a balanced approach between low intensity endurance efforts (typically around 80% of training time) and high intensity interval work (typically around 20% of training time) while almost completely cutting out the intermediate intensities. This approach is favoured by current exercise physiology research [5-9] and is used by many elite endurance athletes [6].
Polarized training is often described in a three zone system with Zones 1, 2, and 3 representing low, intermediate, and hard intensity, respectively. To compare with AIO, we identify Zone 1 with the Endurance zone, Zone 2 with the Tempo and Threshold zones combined, and Zone 3 with the VO2Max and Anaerobic zones combined. These identifications are sensible due to significant intensity overlap.
To explore the predicted performance gains from POL within this study, we restrict the AIO training input space by suppressing training time in the Tempo and Threshold zones. The Endurance, VO2Max and Anaerobic zones are unconstrained.
We study two versions of polarized training: AI optimized polarized (AI-POL) with the same amount of iterations as AIO (30,000) and un-optimized polarized (uPOL) which only uses 3,000 iterations to find the optimal training input. AI-POL represents an optimized polarized training plan that not only follows the polarized principle but also fine-tunes the work in the different sub zones to achieve maximal performance gains. uPOL on the other hand is much less optimized and is more representative of an off-the-shelf, one-size-fits-all polarized training plan.
Threshold training (THR), see for example [3,4], is a training principle that favours interval work at Threshold and Tempo intensities. Typically the balance between Endurance and the Threshold and Tempo intervals is in the 60/40 realm, with little to no intensity in the zones above threshold.
To explore the predicted performance gains from THR within this study, we restrict the AIO training input space by suppressing training time in the VO2Max and Anaerobic zones. The Endurance, Tempo and Threshold zones are unconstrained.
As with POL, we study two versions of threshold training: AI optimized threshold (AI-THR) with the same amount of iterations as AIO (30,000) and un-optimized threshold (uTHR) which only uses 3,000 iterations to find the optimal training input. AI-THR represents an optimized threshold training plan that not only follows the threshold principle but also fine-tunes the work in the different sub zones to achieve maximal performance gains. uTHR on the other hand is much less optimized and is more representative of an off-the-shelf, one-size-fits-all threshold training plan.
Pyramidal training [13] does not aim to avoid the high intensity zones but instead proposes a pyramidal structure with most time spent at low intensities, followed by less but still a substantial amount of time at intermediate intensities and the least amount of time at high intensities. As we are not enforcing a strict static training composition due to the extrapolation constraints discussed above, we group both threshold and pyramidal training under the THR keyword. This is also justified by the optimal THR training compositions for the subjects of this study which can be classified as somewhere in between threshold and pyramidal, see Technical Details section below.
We analyze the predicted improvements for a sample of 126 athlete digital twins which are either runners, cyclists or triathletes. Improvements are measured as changes in 5k pace (runners, triathletes) and/or FTP (cyclists, triathletes) over a training program duration of 8 weeks. The changes are relative to the last recorded performance before the start of the training program.
We limit each individual athlete's training volume by the volume they have trained over the past 8 weeks. On average, the training volume of the population was 4.7 hours/week. This is to see what improvements can be achieved with the same training volume an athlete is already accustomed to and might be restricted to. The average FTP prior to the training program is 248 Watts and the average 5k pace is 4:33 min/km (7:20 min/mi).
As a baseline, we let each athlete repeat the last 8 weeks of their training and infer the predicted change in performance. We use AI Endurance's optimization engine to create a training plan for each of the training routines discussed: AIO, AI-POL, AI-THR, uPOL, and uTHR. Predicted performance changes are inferred from these training plans with an individual prediction error for each athlete. We aggregate these results into mean predicted improvements (see Technical Details section below).
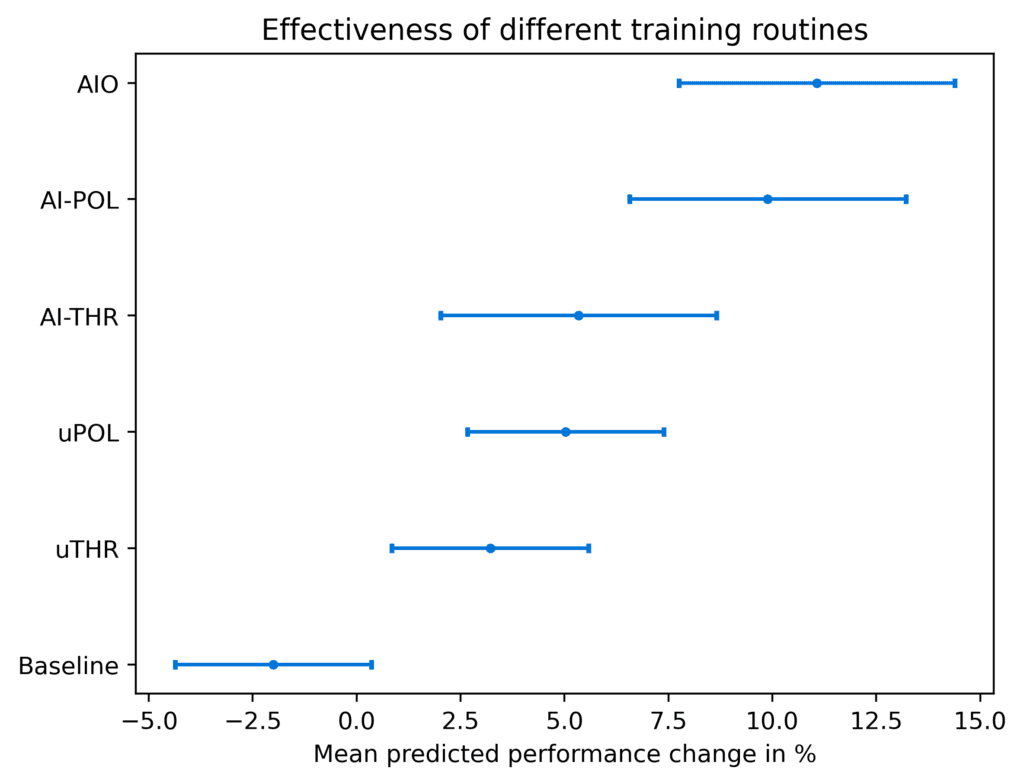
The baseline result is that if the athletes repeat their training no performance improvements are seen. There is a very significant (greater than 3-sigma, p<0.002) finding that AIO training leads to performance improvement relative to the baseline. For the training programs, there is a clear hierarchy as AIO and AI-POL training predict larger gains than the less optimized uPOL and uTHR routines.
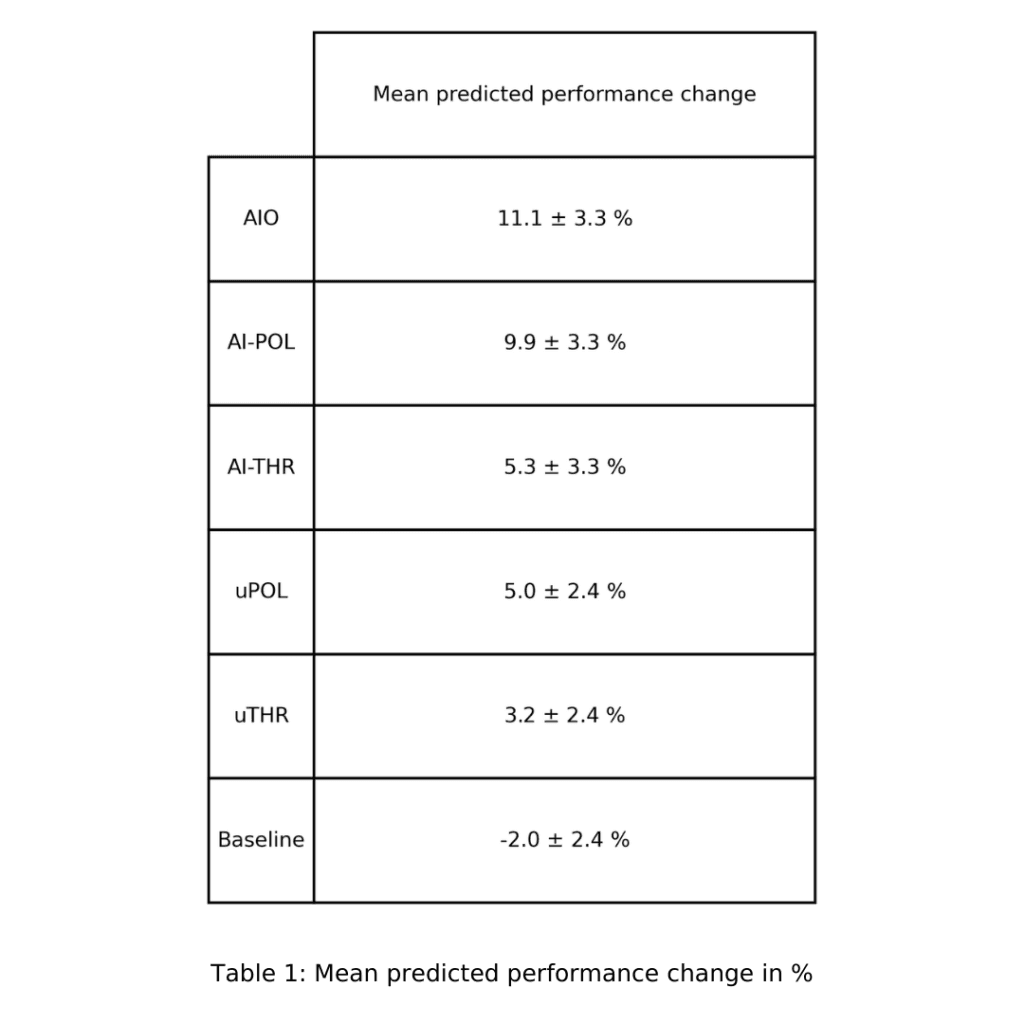
Unsurprisingly, AIO achieves better results than AI-POL and AI-THR in the fully optimized category as it has a larger parameter space available than the two latter. AI-POL and AI-THR are pigeon-holed into the respective training philosophies while AI is completely unbiased towards these. However, for most athletes if you would choose a training philosophy bias, POL is much better than THR.
AI-POL realizes better gains than AI-THR for 89% (112) of athletes while AI-THR is better than AI-POL in only 11% (14) of cases. Also the gains are generally higher for AI-POL compared to AI-THR. These two findings combined, explain the strong overlap for predicted performance changes between AIO and AI-POL.
For more information on the errors and machine learning techniques see Technical Details below.
More recent endurance exercise physiology research generally favours POL over THR, see for example [2, 5-9]. [5] is a study with 48 endurance athletes, finding significant improvement with POL in VO2Peak (+11.7%, p<0.01) and velocity/power at 4 mmol/L (+8.1%, p<0.01), and other indicators, while finding no significant improvements from THR. [6] finds that the elite endurance athletes generally follow the POL approach. [7] is a meta analysis which combines 4 randomized controlled trials with a combined 329 results, finding that POL is preferred over THR at moderate effect size. [2] finds THR leads to 3.6% improvements, while POL leads to 5.0% improvement in a study of 10k times with 30 recreational runners.
Performance indicators in these studies are not identical with this study (FTP, 5k pace). However, on a qualitative level, the results are in agreement. In particular, the lack of evidence supporting THR and the general trend that POL is preferred over THR is reflected in our results.
We would further like to comment on the sample sizes. The meta analysis of [7] includes a total of 329 results. Our study, while only using the historical exercise data of 126 athletes already includes 6 x 126 = 756 results (not counting the tens of thousands of optimization steps). This clearly outlines the potential of machine learning based or supplemented studies to overcome the cost and duration challenges of conventional randomized controlled trials. A future avenue could be to anchor machine learning based simulations with 'real life athlete' study results to get the best of both worlds. Similar possible ways to use neural networks in this context have been suggested in [11,12].
As displayed in Table 1, uPOL and uTHR have central values of almost a factor 2 (1.7) less than their AI counterparts. These improvements are due to more nuanced adjustments of an individual's training plan as opposed to just roughly following the training philosophy. uTHR is not found to be a significant improvement over the baseline.
The improvement of AIO over uPOL is significant at 1.5-sigma while AIO over uTHR is significant at 1.9-sigma. As discussed in the previous section, POL generally yields better results for a higher number of athletes than THR. However, from the perspective of an individual athlete, they might be part of the 11% that benefit from a more THR-like training composition. Hence, an unbiased and personalized search for the ideal training composition is important.
AIO as described in this study is enabled for every AI Endurance user by default. You can benefit from this truly data-driven, predictive and research-proven approach to training by signing up to AI Endurance.
The number of participants is a crucial factor for the quality and implications of a study such as this one. If you are using AI Endurance, you can allow us to use your data to publish research studies about the effectiveness of endurance training such as this one. These studies can help move exercise research forward and help your fellow athletes achieve their goals. We are extremely conscious of your privacy concerns. Your data would always remain anonymous, i.e. your name or any performance values will never be published. The data would only be published in aggregate form, such as: 'On average x training composition helped athletes improve by y percent.'
If you want to allow AI Endurance to use your data in studies such as this one, simply check this box in your Account page and press 'Save Changes'
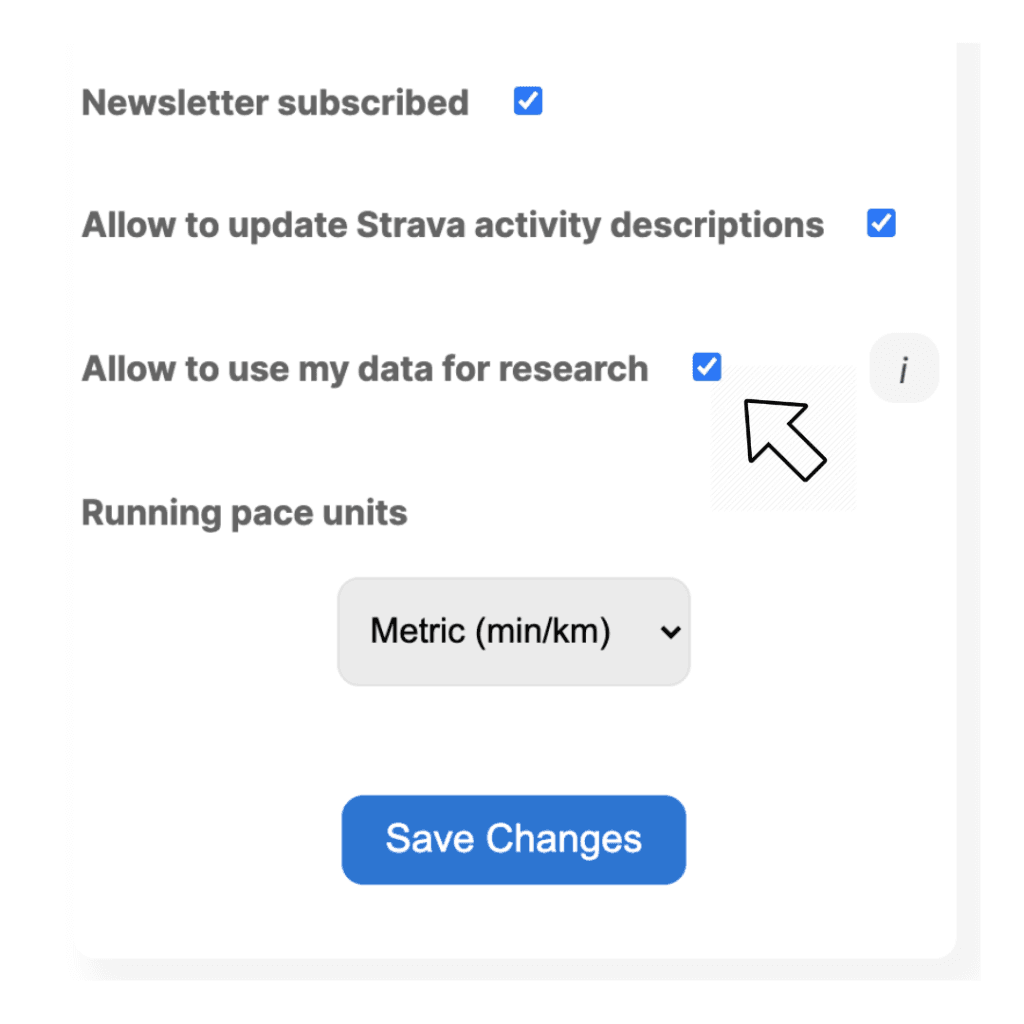
By default this box is unchecked, i.e. your data will never enter any public research without your consent.
This section provides additional technical background on this study:
This study was performed by AI Endurance. To protect the privacy of participants, we are not publishing any absolute performance values, only relative improvements and aggregate data on training compositions. To protect our intellectual property we are not planning on publishing any further details on the underlying AI algorithm.

When it comes to triathlon training, nutrition plays a vital role in fueling your performance and optimizing your results. To help you reach peak performance, we have developed an advanced AI meal plan that takes into account your unique requirements, respects the calorie cost of your workouts, and accommodates your dietary preferences. With the power of evidence-based nutrition models, we ensure that your triathlon meal plan is tailored to support your goals.

by Markus Rummel. DDFA (Dynamical Detrended Fluctuation Analysis) is a new method to analyze the changes in your HRV data during exercise. It is an evolution of the DFA analysis based on the research in [1, 2] used by AI Endurance.

Use Zwift running workouts to increase your running pace with a data-driven, personalized and predictive Zwift running training plan from AI Endurance.
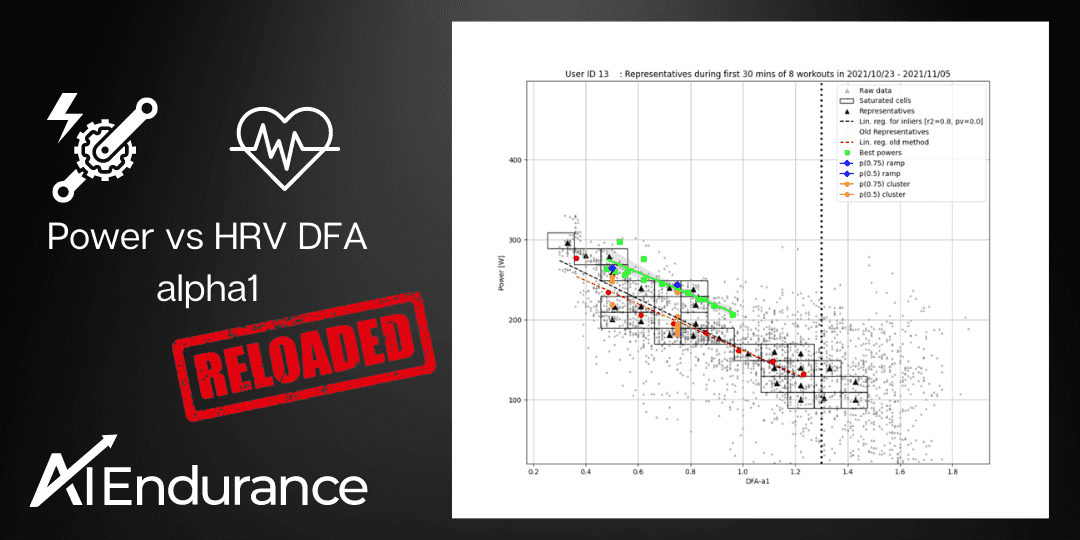
by Stefano Andriolo. Building on previous work, we refine a method to accurately determine the relationship between DFA alpha 1 and power. This method can be used to track fitness and thresholds of an athlete. We find in some cases ramp detection tends to overestimate thresholds, a finding mirrored in recent physiological papers. On the other hand, thresholds based on clustering of DFA alpha 1 values tend to agree well with this new method. We propose a hybrid lab and everyday workout experiment to further study the relationship.